教育行业AI应用解决方案
方案描述
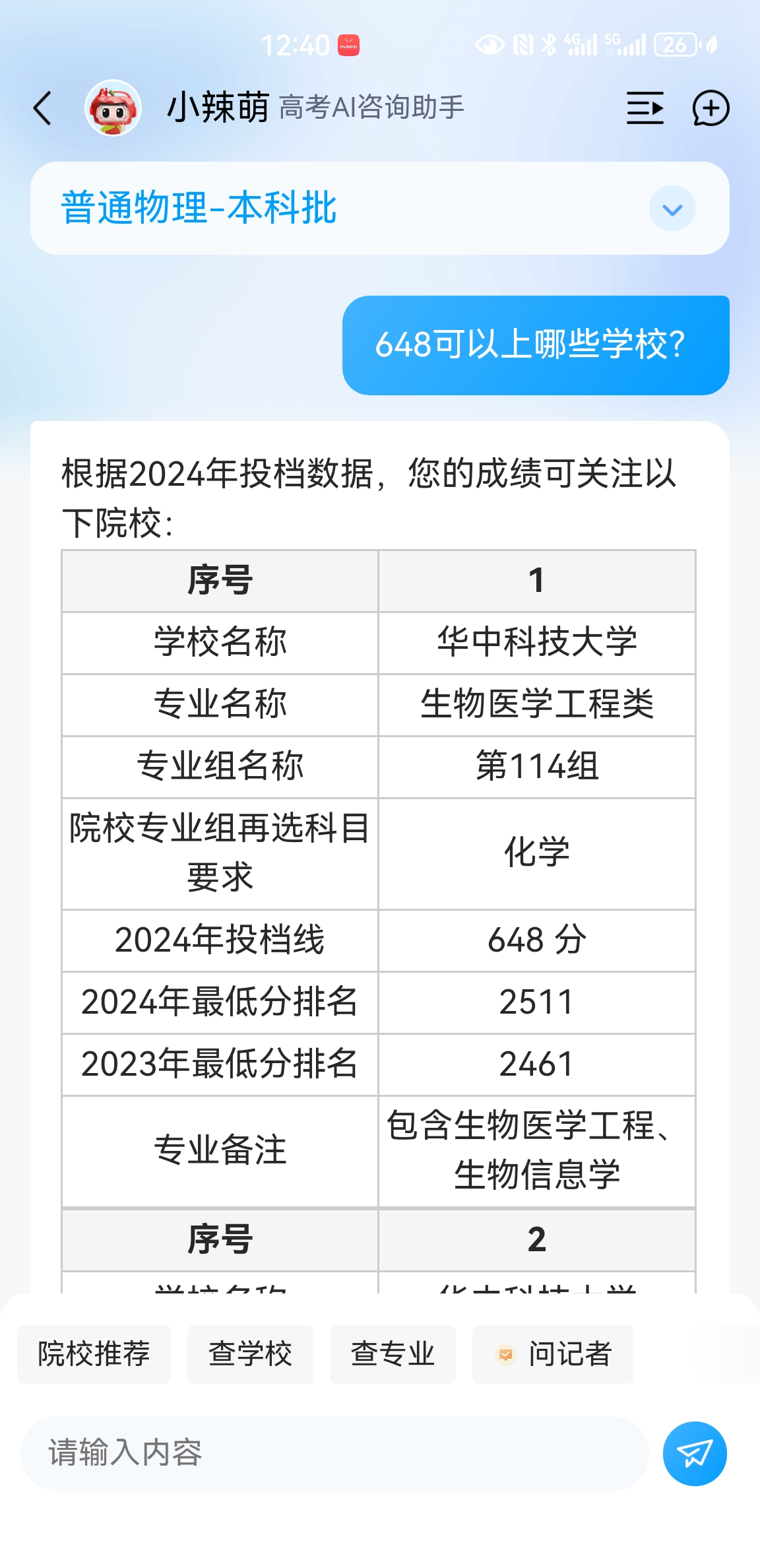
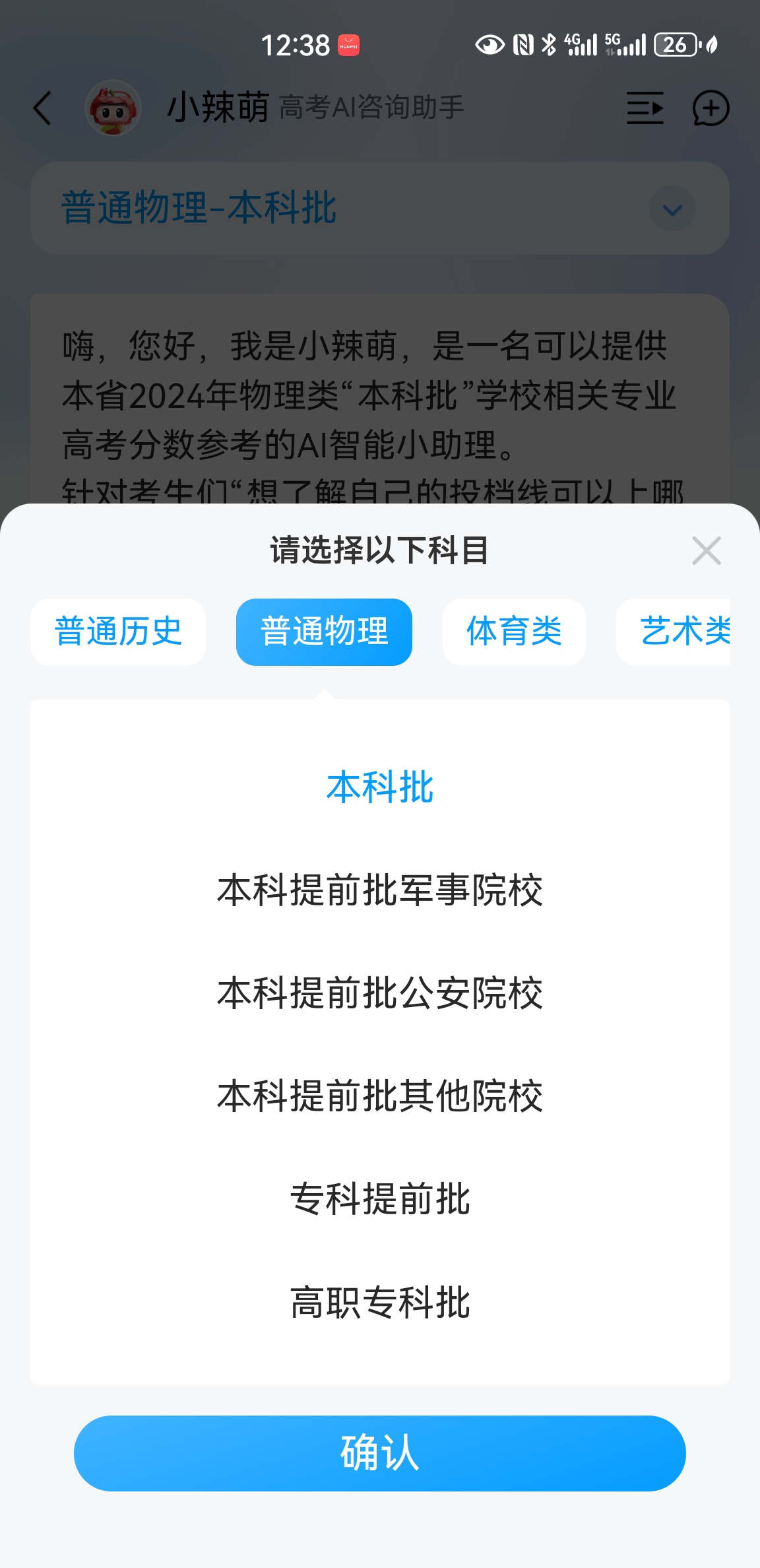
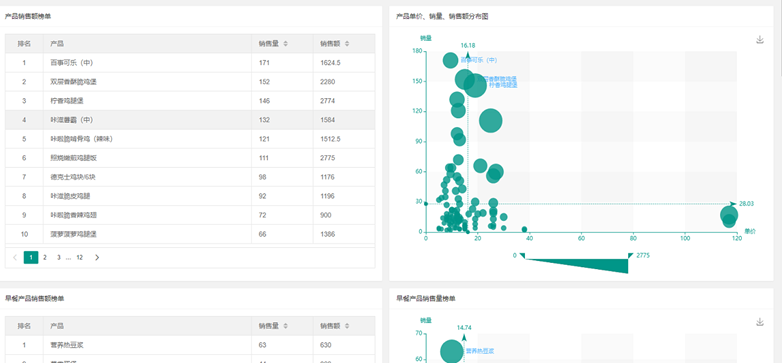
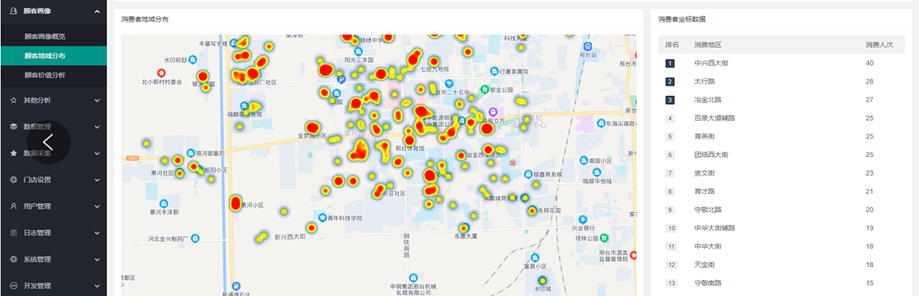
面向湖南省高考考生,提供便捷、可靠的高考成绩查询服务,并基于查询过程中产生的可公开、脱敏数据,构建面向教育类工作室的高价值内容创作支持体系。通过整合大模型智能分析与多维度数据服务,助力合作教育工作室快速、准确地生成优质高考相关新闻与解读内容
方案优势
高效模型基础
搭载先进的Deepseek-V3大模型,提供强大、稳定的自然语言处理与数据分析能力,确保内容生成的高质量与智能性。
可视化工作流构建
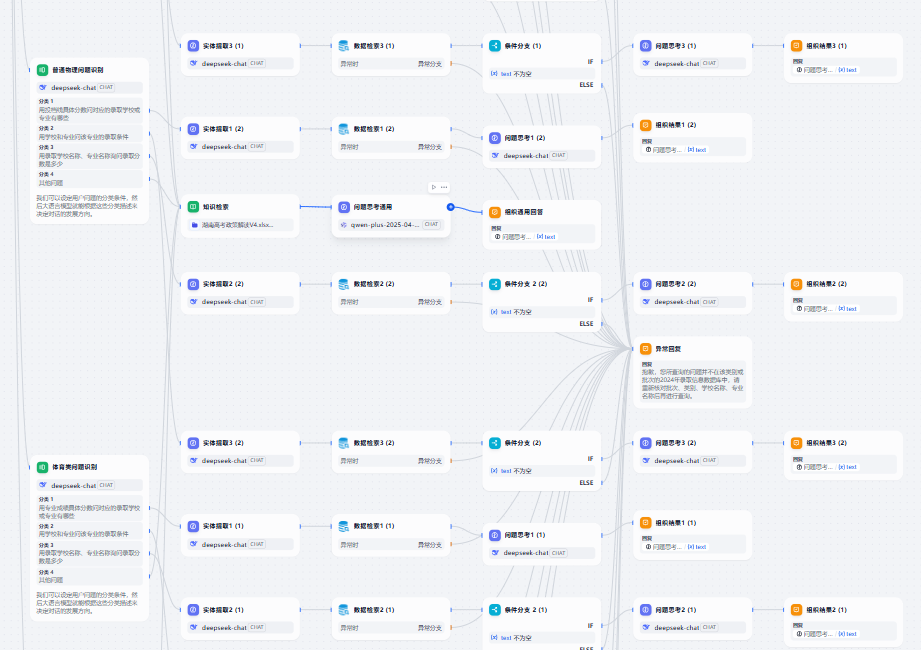
依托Dify平台灵活构建与部署模型应用流程,实现业务逻辑的快速迭代和高效维护,大幅降低开发与运维门槛。
精准知识检索
基于RAG(检索增强生成)技术构建专用知识库,加强对政策文件、历年数据的结构化理解与引用,显著提升内容输出的准确性与可靠性。
智能调控与优化
通过系统化的提示词工程与MCP(模型控制协议)技术,精细调控模型生成行为,关键问答准确率提升至99%,有效保障输出内容的可信度与适用性。
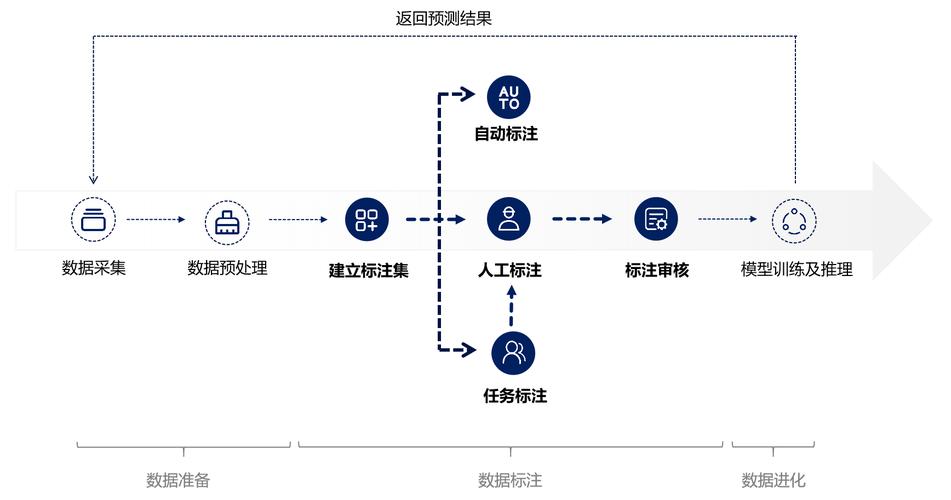
数据服务流程
官方文档解析:对教育主管部门发布的电子文档进行精准解析与清洗,转化为高质量的结构化数据。
关键信息标注:系统自动识别并标注核心数据字段,如分数段分布、区域统计、学科优势等,为内容创作提供清晰的数据支撑。
专业数据校准:配备专业数据分析团队进行二次核验与校准,确保所有输出数据真实、可靠,符合新闻传播与政策导向要求。